다중공선성을 판단하기 위해 VIF 가 가장 많이 사용된다. VIF 수식의 값이 10 이상 이면 해당 변수가 다중공선성이 존재하는 것으로 판단한다. (반대로, 1 에서 10 미만의 값이면 다중공선성이 별 문제가 되지 않는 것으로 판단한다. 참고로 VIF 값은 1에서 무한대의 값의 범위를 갖는다.)
다중공선성을 SPSS 프로그램을 사용하여 측정할 수 있다. 만약, SPSS 에서 다중공선성(VIF, Tolerance, CN) 을 계산하는 방법을 알고 싶다면 여기 를 클릭하면 설명을 볼 수 있다.
VIF 수식의 의미는 아래에 자세하게 설명하였다.
VIF 에 대한 설명
데이터의 다중공선성을 진단하는 방법 중 가장 많이 사용되고 있는 VIF 에 대해서 설명한다.
VIF 는 'Variation Inflation Factor' 의 줄임말이다.
한글로는 '분산 확대 인자' 또는 '분산 팽창 계수' 또는 '분산 팽창 요인' 등으로 불린다.
VIFk 는 k 번째 변수의 다중공선성의 정도를 의미한다. 즉, VIF 는 입력 데이터 전체의 다중공선성 정도를 하나의 수치로 제시하는 것이 아니라, 각각의 입력 변수들을 대상으로 계산된다.
VIFk 의 계산 방식을 설명하겠다.
설명에 앞서 먼저 입력 데이터의 구성을 아래와 같이 약속하자.
분석에 사용될 데이터가 입력변수 n개와 종속변수 1개로 구성된다고 하자. 총 변수는 n+1 이다.
이 데이터의 변수들은 모두 수치형(양적) 변수이어야 한다.
그럼, VIFk 는 (여기서, 1<= k <= n 의 관계)
변수 k를 종속변수로 지정하고, 나머지 n-1 개의 입력변수를 입력변수로 지정하여 회귀분석을 수행한다.
즉, 이 회귀분석에서 종속변수 Y는 제외시킨다. 왜냐하면, 다중공선성은 입력변수들 간의 상관관계를 측정하는 것이기 때분이다.
위 수행된 회귀분석에서의 결정계수 Rj2 을 구한 후 아래의 수식으로 VIFk 를 구한다.
VIFk = 1 / (1 - Rj2)
VIFk 는 k번째 변수의 VIF 값을 의미한다.
결정계수 Rj2 값은 0에서 1의 값을 가지므로 VIF 값은 1에서 무한대의 범위를 갖는다.
(1) 결정계수 Rj2 값이 0에 가깝다는 것은 입력변수 k가 다른 입력변수들과 상관성이 거의 없다는 것을 의미하고, (2) 결정계수 Rj2 값이 1에 가깝다는 것은 입력변수 k가 다른 입력변수들과 상관성, 즉 다중공선성이 크다는 것을 의미한다.
다시 얘기하면,
VIF 값이 1 에 가까울수록 다중공선성의 정도가 작은 것이며, 반대로 값이 커질수록 다중공선성의 정도가 큰 것을 의미한다.
값의 범위가 1에서 무한대이기 때문에, 어느정도 커야 다중공선성이 있다라고 판단할 것인가에 대한 기준값이 필요하다. 보통 VIF 값이 10 이상인 경우 해당 변수가 다중공선성이 있다고 판단한다.
생각해볼 문제.
항목1. VIF 수식은 회귀분석에만 사용될 수 있다. 즉, 수치형으로 구성된 데이터에 대해서만 적용가능하다. 결정트리 알고리즘에 적용하기 위한 데이터의 다중공선성 진단에는 적용할 수 없는가? 수치형 뿐 아니라 범주형도 섞여있는 데이터으므로 적용이 안되지 않는가?
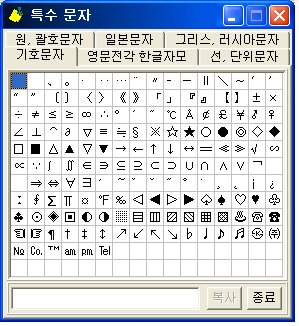
특수문자.exe 를 실행하면 아래와 같이 단순한 화면이 보인다.
상단의 탭 구분을 눌러 한번에 자신이 원하는 특수문자를 찾을 수 있다.
원하는 코드를 더블클릭 하면 화면 하단 텍스트박스에 입력된다.
하단의 [복사] 버튼을 누른 후, 작업하던 프로그램에 와서 붙여넣기(Ctrl+V)를 실행하면 된다.
추가적인 특수문자 입력방법
위 프로그램을 사용하지 않고 직접 원문자 등의 특수문자를 입력하는 방법에 대한 자료를 링크한다. 특히, 엑셀 등의 오피스 프로그램을 사용할 때 특수문자를 입력하는 방법을 몰라 헤맬때가 있는데 아래의 자료를 참고하면 도움이 된다. (한글 자음 키를 누른 후 [한자키]를 누른다. 예를 들어 O 을 입력한 후 한자키를 누르면 원문자가 나타난다. 자세한 내용은 아래 클릭~)
데이터마이닝 및 기계학습에서 오픈소스 및 공개 프로그램으로 유명한 웨카(Weka) 프로그램에 대해서 설명합니다. 아래의 3개의 주제로 글을 작성하여 <해당글>을 작성한 후 링크하였습니다.
(1)에서는 웨카 프로그램을 누가 만들었으며 어떻게 사용될 수 있는지 설명하고, (2)에서는 웨카 프로그램을 다운로드 받고 설치하고 실행하는 방법을 설명합니다. (3)에서는 웨카 프로그램을 사용하여 기본적으로 설치되는 IRIS 데이터를 가지고 의사결정트리 분류 분석을 수행하는 방법을 설명하였습니다.
⊙ 뉴질랜드 와이카토 대학교의 컴퓨터 과학과에서 개발한 기계 학습 라이브러리인 웨카(WEKA, http://www.cs.waikato.ac.nz/ml/weka/)가 미국 컴퓨터 학회의 데이터 마이닝 분과인 SIGKDD(http://www.acm.org/sigs/sigkdd/)에서 수여하는 상을 수상했다. 웨카는 자바 언어로 구축된 무료 라이브러리로, 그동안 국제적으로 널리 사용되어 왔다.
⊙ 이제 처음 도입된 지 약 10여 년이 넘은 데이터 마이닝 분야에서 이 상은 가장 권위있는 상이다. 이는 데이터 마이닝 분야에서 훌륭한 실적을 낸 학자나 연구팀에게 수여하는 상으로, 특히 와이카토 대학교의 컴퓨터 과학과는 지난 해 디지털 도서관 연구와 관련해 국제적인 학술상을 수여 받은 데 이어 2년 연속으로 영광을 안게 됐다.
⊙ 웨카는 '지식 분석을 위한 와이카토 환경(Waikato Environment for Knowledge Analysis: WEKA)'의 약자로, 국제적으로 이 분야 교과서로 많이 쓰이고 있는 '데이터 마이닝: 실용적인 기계 학습 도구와 기술(http://www.cs.waikato.ac.nz/~ml/weka/book.html)'이라는 책과 더불어 무료 소프트웨어로 개발된 것이다.
⊙ 웨카 개발을 총지휘한 사람은 이 대학교의 이안 위튼(Ian Witten, http://www.cs.waikato.ac.nz/~ihw/) 교수다. 문서 위주의 데이터 마이닝 기법과 디지털 도서관 관련 기술이 전공인 위튼은, 대학 또는 대학원의 교과 학습이나 그 외 연구 목적에서 누구나 쉽게 사용할 수 있는 범용 기계 학습 라이브러리로 웨카를 개발한 것이다. 웨카는 오픈소스 소프트웨어이기 때문에 누구나 원하는 코드를 덧붙이거나 수정하여 사용할 수 있다는 점도 큰 장점이다.
⊙ 웨카에는 일반적으로 데이터 마이닝 분야에서 필요로 하는 기본적인 알고리즘들이 대부분 구현되어 있다. 예를 들면 문서를 자동으로 분류하는데 사용되는 베이지언 네트워크나, 문서의 자동 군집화에 사용되는 'k-means' 알고리즘, 예측 규칙 도출을 위한 ID4 알고리즘, 어소시에이션 규칙(association rules) 추출 알고리즘 등 교과서에 나오는 기계 학습 알고리즘들이다. 사용자들은 간단한 인터페이스를 통해 이런 알고리즘들을 불러 사용할 수 있으며, 그 결과를 그래프로 쉽게 표현해 파악할 수 있다.
⊙ 2000년 4월부터 웨카의 내려받기 횟수는 20만 회를 상회하는데, 최근에는 한달에 1만회의 내려받기를 보이며 매우 높은 인기를 끌고 있다. SIGKDD의 시상은 다음 달에 시카고에서 열리는 연례 학술회의(http://www.acm.org/sigs/sigkdd/kdd2005/)에서 이루어질 예정이다.
패턴인식이란 자동적으로 어떤 개체를 인식하는 기술을 의미합니다.
패턴을 인식한다? 말이 어렵게 들릴 수 있는데 예를 들어 설명해보겠습니다.
사람은 기본적으로 패턴을 인식할 수 있는 엄청난 능력을 가지고 있습니다.
종이에 흘겨 쓴 글자를 인식하여 그것이 '가' 인지 '거' 인지 (또 다른 글자인지) 구분(인식)할 수 있으며,
어떤 물체가 나타났을 때 사람인지 강아지인지 자동차인지 등을 구분(인식)할 수 있습니다.
패턴인식이란 프로그램이 또는 기계가 사람과 같이 인식하게 하여 특정 영역에 활용하는 연구 분야입니다. 예를 들어, 사람이 쓴 글자를 인식한다거나, 비디오에서 사람의 얼굴을 인식하거나 자동차의 번호판을 인식하는 것 등을 패턴인식의 대표적인 문제로 들 수 있습니다.
패턴인식은 인공지능을 위해 사용되는 필수적인 기술입니다. 우리가 기대하고 있는 인공지능 로봇은 사람을 알아봐야 하고 길을 찾아 걸을 수도 있으며, 우리가 부르면 들을 수 있고 어떤 명령을 하면 그 의미를 인식하여 수행해야 합니다. 즉, 시각적 인식, 청각적 인식 능력이 있어야 하겠지요.
이런 의미에서, 인공지능을 넓은 범주로 본다면 그 안에 속하는 하나의 세부 연구분야라고 볼 수 있습니다.
패턴인식 활용 예
(1) 무인 자동차
자동 주행 자동차; 사람이 운전하지 않고 자동차 스스로 도로, 길을 인식하여 운행하도록 함.
인공지능이란 컴퓨터 프로그램이 또는 기계가 사람과 같은 지능을 갖고 행동하도록 하는 학문이다.
쉽게 생각하면 만화영화를 통해 익숙한 아톰 이라는 로봇을 생각해보자. 아톰과 같은 로봇을 만들기 위해 어떤 기술들이 필요할까? 바로 그 내용에 해당하는 모든 것들이 인공지능 기술의 범주에 속한다고 보면 된다.
아톰과 같은 로봇을 만들기 위해 어떤 기술이 필요할지 생각해보자.
로봇은 눈을 가지고 볼수 있으며, 소리(말)을 들을 수 있어야 한다. (시각인식, 음성인식)
로봇은 외부 환경이나 또는 자신의 행동의 성공과 실패를 통해서 학습할 수 있어야 한다. (학습능력)
로봇은 스스로 판단하고 행동할 수 있어야 한다. (에이전트 기술, 전문가 시스템)
스스로 이동할 수 있어야 한다. (이족 이동 로봇)
로봇은 도덕적인 기준을 가지고 행동하여야 한다.
위의 로봇을 만들기 위한 인공지능 기술들은 다양한 분야에 적용될 수 있다.
정확히 말하면, 인공지능의 적용은 꼭 아톰과 같이 사람을 닮은 로봇(휴머노이드 로봇)만을 의미하지는 않는다. 눈에 보이지 않는 컴퓨터 프로그램, 공장이나 가정의 기계 등 음성이나 시야를 인식하는 능력, 스스로 판단하고 행동하는 능력, 환경으로 부터 또는 스스로의 행동의 실수나 성공으로 부터 학습하는 능력 등의 일부를 가지고 있다면 우리는 그 것을 인공지능이라고 부른다.
인공지능의 활용 분야
인공지능 기술은 많은 사람들이 동경하는 휴머노이드 로봇을 개발하는 것에서 부터 시작하여,
실생활의 다양한 분야에 적용되고 있다.
휴머노이드 로봇의 개발 [상세보기]
무인 자동차 [상세보기]
청소기 로봇 [상세보기]
군사용 로봇 [상세보기]
문자인식 프로그램 [상세보기]
음성인식 프로그램 [상세보기]
로봇 축구 [상세보기]
또는 게임의 캐릭터가 스스로 움직이며, 실패를 통해 학습하고, 갈수록 더 지혜롭게 움직이게 되는 것을 생각할 수도 있겠다. 요즘 출시된 청소로봇 도 인공지능의 기술을 단면을 보여준다.
 특수문자 프로그램.zip
특수문자 프로그램.zip

 ExplorerGuide.pdf
ExplorerGuide.pdf weka_usage.ppt
weka_usage.ppt [교재] Weka를이용한DM학습(2008-10-14).hwp
[교재] Weka를이용한DM학습(2008-10-14).hwp

RECENT COMMENT