참조:
http://blog.naver.com/ibuyworld/110048919032정리 : 데이터의 다중공선성 및 상호작용(매개효과?)에 대해서 설명하고 있다.
내용 :
기업의 시가총액에 재무전략이 미치는 영향을 알아보기 위해 Data set을 모은다라고 가정하자,
Response Variable = Market Capitalization
Predictor Variabl = Debt, Debt-Equity Ratio, ROE, ROA, Aseet
위의 6가지의 독립변수로 시가총액과의 관계를 infer할 때 각 Time series가 아닌 이상 each X는 상호 독립성을 유지해야 하는게 regression의 assumption이기 때문에 서로 영향을 주고 있음이 정확히 나타난다.
Debt-Equity는 Debt이 증가하면서 같이 증가하고, DE ratio의 E가 하락하면서 ROE를 높인다. 또한 ROA와 Asset은 밀접한 관계를 가지고 있다. Regression Analysis는 주어진 모델에서 다른 X-변수가 (all other variables are hold constant) 변화없이 정지된 상태에서 Debt만의 효과를 coefficient(Value)와 Standard Error(95% CI or whatever)로 확인하는데 의미가 있는데 X간에 독립적이지 못 하면 서로 영향을 미쳐 주어진 Outcome은 misled하게 된다. 필요없이 많은 자료, 특히 필요없는 새로운 항목은 잘못된 의사결정을 유도하고 자료를 모으는 비용을 발생시킨다.
다른 하나의 X가 움직이는 동안 또 다른 하나가 고정되지 못하기 때문에 해당 X의 coefficient를 해석해 내지 못할 위험이 있고 하나를 제거하면 하나 이상을 제거하는 효과가 있어 Y의 평균값의 분산이 매우 커지게 된다.
이를 다중공선성 (or Multicollinearity, 오히려 영어가 다 쉬운듯 하다.) 이라고 한다. 서로간의 이런한 영향력을 가지고 있다면 하나를 제거해 줘야 하는데 통계페키지에서 VIF 값을 가지고 사용한다.
참고로 다중공선성과 Interaction effect는 완전히 다른 개념이다. 다중공선성은 Numerical Variables간의 독립성여부를 확인하는 것이지만 interaction effect는 연구에서 중요하게 관심을 가지는 X간의 상호관계를 확인하는 것이다. 즉, numerical variable에 categorical variable이 적용되면 Y의 평균이 어떻게 달라지냐의 연구에 중요한 부분이다. X를 90 넣고 제초제를 applied하지 않을 때의 꽃의 생산율이 90인데 X를 90넣고 제초제를 뿌리니깐 꽃의 생산율이 120 이다. 제초제 자체가 꽃 생산에 영향을 미치기도 하지만 X와 제초제의 혼합효과 또한 꽃의 생산율에 영향을 미치기도 한다. 이를 interaction effect라고 하는데 이게 통계적으로 유의한지에 대해서는 Extra-sum of square F test로 확인하기 바란다.
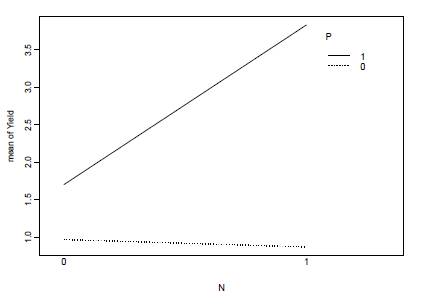
참고로 아래에 interaction effect 관련 그래프를 하나 붙여본다. P가 있고 없음의 차이가 N이 없을 때의 Y값의 차이와 N이 있을 때의 Y값의 차이가 다른 것을 확인할 수 있다. 이는 N과P의 interaction effect가 있다는 것이다. 이 그래프에서 N과 P의 combination이 없었다면 Y값은 작아져서 점선과 직선이 수평을 이루었을 것이다. 대표적으로 두선이 교차하면 interaction이 있다고 본다.
이 상호효과는 기업전략의 핵심역량이론과 상당히 닮아있다. 2000년대 초반은 미국시장에서 토요타, 혼다가 GM, Ford를 압도하기 시작한 시점이었다. 그래서 토요타에 대한 연구가 미국에서 많았는데 토요타의 생산방식을 미국에 적용해도 그 효과가 나타나지 않는다는 이유가 바로 핵심역량의 이유였다. 기술이 이전되고 모방을 해도 원적용자의 효과를 따라갈 수가 없는데 이는 생산시설, 기업문화, 조직, 공급망등 모든 요소가 상호작용해서 이미 main effect(주효과: X만의 효과)만을 가지고 기업의 시장점유율을 높일 수도 없었고 interaction effect가 통계적으로도 큰 의미있는 것으로 보여주고 있다. Interaction effect는 원적용자또한 정확한 투입비율을 알 수가 없다는 것이다. 200년된 양조장에서 나오는 술맛을 그대로 재현하기 위해 그 주인이 새로운 양조장을 만들어 동일한 제조비율로 만든다고 해도 동일한 맛은 나오지 않는다. 200년된 양조장의 manual에 없는 무언가의 상호작용으로 고객을 이끈다. 새롭게 확장되는 사업망은 기존 핵심역량을 가지고 있는 양조장의 brand에 악영향을 미칠 가능성이 높다.
기업전략에서또한 기업가치를 높이는데 투입하는 요소가 서로 다중공선성(중복된 투자효과)이 없는지 확인하고 interaction effect를 최대한 높여가는 노하우에 대한 지식경영이 중요한 시점이다.
 invalid-file
invalid-file weather.csv
weather.csv



RECENT COMMENT